
2.7 Implementing Common Control Structures in Assembly Language
Since a primary goal of this chapter is to teach you how to use the low-level machine instructions to implement decisions, loops, and other control constructs, it would be wise to show you how to simulate these high level statements using "pure" assembly language. The following sections provide this information.
2.8 Introduction to Decisions
In its most basic form, a decision is some sort of branch within the code that switches between two possible execution paths based on some condition. Normally (though not always), conditional instruction sequences are implemented with the conditional jump instructions. Conditional instructions correspond to the IF..THEN..ENDIF statement in HLA:
if( expression ) then << statements >> endif;Assembly language, as usual, offers much more flexibility when dealing with conditional statements. Consider the following C/C++ statement:
if( (( x < y ) && ( z > t )) || ( a != b ) ) stmt1;A "brute force" approach to converting this statement into assembly language might produce:
mov( x, eax ); cmp( eax, y ); setl( bl ); // Store X<Y in bl. mov( z, eax ); cmp( eax, t ); setg( bh ); // Store Z > T in bh. and( bh, bl ); // Put (X<Y) && (Z>T) into bl. mov( a, eax ); cmp( eax, b ); setne( bh ); // Store A != B into bh. or( bh, bl ); // Put (X<Y) && (Z>T) || (A!=B) into bl je SkipStmt1; // Branch if result is false (OR sets Z-Flag if false). <Code for stmt1 goes here> SkipStmt1:As you can see, it takes a considerable number of conditional statements just to process the expression in the example above. This roughly corresponds to the (equivalent) C/C++ statements:
bl = x < y; bh = z > t; bl = bl && bh; bh = a != b; bl = bl || bh; if( bl ) stmt1;Now compare this with the following "improved" code:
mov( a, eax ); cmp( eax, b ); jne DoStmt; mov( x, eax ); cmp( eax, y ); jnl SkipStmt; mov( z, eax ); cmp( eax, t ); jng SkipStmt; DoStmt: << Place code for Stmt1 here >> SkipStmt:Two things should be apparent from the code sequences above: first, a single conditional statement in C/C++ (or some other HLL) may require several conditional jumps in assembly language; second, organization of complex expressions in a conditional sequence can affect the efficiency of the code. Therefore, care should be exercised when dealing with conditional sequences in assembly language.
Conditional statements may be broken down into three basic categories: IF statements, SWITCH/CASE statements, and indirect jumps. The following sections will describe these program structures, how to use them, and how to write them in assembly language.
2.8.1 IF..THEN..ELSE Sequences
The most common conditional statement is the IF..THEN or IF..THEN..ELSE statement. These two statements take the form shown in Figure 2.1:
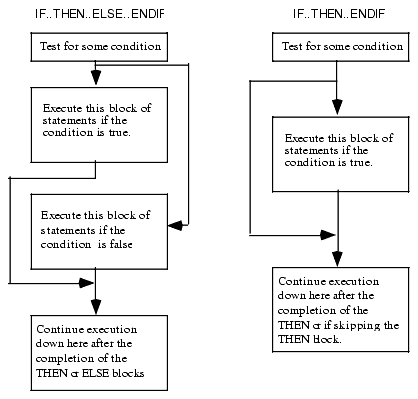
Figure 2.1 IF..THEN..ELSE..ENDIF and IF..ENDIF Statement Flow
The IF..ENDIF statement is just a special case of the IF..ELSE..ENDIF statement (with an empty ELSE block). Therefore, we'll only consider the more general IF..ELSE..ENDIF form. The basic implementation of an IF..THEN..ELSE statement in 80x86 assembly language looks something like this:
{Sequence of statements to test some condition} Jcc ElseCode {Sequence of statements corresponding to the THEN block} jmp EndOfIFElseCode: {Sequence of statements corresponding to the ELSE block}EndOfIF:Note: Jcc represents some conditional jump instruction.
For example, to convert the C/C++ statement:
if( a == b ) c = d; else b = b + 1;to assembly language, you could use the following 80x86 code:
mov( a, eax ); cmp( eax, b ); jne ElsePart; mov( d, c ); jmp EndOfIf; ElseBlk: inc( b );EndOfIf:For simple expressions like "( a == b )" generating the proper code for an IF..ELSE..ENDIF statement is almost trivial. Should the expression become more complex, the associated assembly language code complexity increases as well. Consider the following C/C++ IF statement presented earlier:
if( (( x > y ) && ( z < t )) || ( a != b ) ) c = d;When processing complex IF statements such as this one, you'll find the conversion task easier if you break this IF statement into a sequence of three different IF statements as follows:
if( a != b ) C = D; else if( x > y) if( z < t ) C = D;This conversion comes from the following C/C++ equivalences:
if( expr1 && expr2 ) stmt;if( expr1 ) if( expr2 ) stmt;if( expr1 || expr2 ) stmt;if( expr1 ) stmt; else if( expr2 ) stmt;In assembly language, the former IF statement becomes:
// if( (( x > y ) && ( z < t )) || ( a != b ) ) // c = d; mov( a, eax ); cmp( eax, b ); jne DoIF; mov( x, eax ); cmp( eax, y ); jng EndOfIF; mov( z, eax ); cmp( eax, t ); jnl EndOfIf; DoIf: mov( d, c ); EndOfIF:As you can probably tell, the code necessary to test a condition can easily become more complex than the statements appearing in the ELSE and THEN blocks. Although it seems somewhat paradoxical that it may take more effort to test a condition than to act upon the results of that condition, it happens all the time. Therefore, you should be prepared for this situation.
Probably the biggest problem with the implementation of complex conditional statements in assembly language is trying to figure out what you've done after you've written the code. Probably the biggest advantage high level languages offer over assembly language is that expressions are much easier to read and comprehend in a high level language. This is one of the primary reasons HLA supports high level language control structures. The high level language version is self-documenting whereas assembly language tends to hide the true nature of the code. Therefore, well-written comments are an essential ingredient to assembly language implementations of if..then..else statements. An elegant implementation of the example above is:
// IF ((X > Y) && (Z < T)) OR (A != B) C = D; // Implemented as: // IF (A != B) THEN GOTO DoIF;mov( a, eax ); cmp( eax, b ); jne DoIF;// if NOT (X > Y) THEN GOTO EndOfIF;mov( x, eax ); cmp( eax, y ); jng EndOfIF;// IF NOT (Z < T) THEN GOTO EndOfIF ;mov( z, eax ); cmp( eax, t ); jnl EndOfIf;// THEN Block:DoIf: mov( d, c );// End of IF statementEndOfIF:Admittedly, this appears to be going overboard for such a simple example. The following would probably suffice:
// if( (( x > y ) && ( z < t )) || ( a != b ) ) c = d; // Test the boolean expression:mov( a, eax ); cmp( eax, b ); jne DoIF; mov( x, eax ); cmp( eax, y ); jng EndOfIF; mov( z, eax ); cmp( eax, t ); jnl EndOfIf;; THEN Block:DoIf: mov( d, c );; End of IF statementEndOfIF:However, as your IF statements become complex, the density (and quality) of your comments become more and more important.
2.8.2 Translating HLA IF Statements into Pure Assembly Language
Translating HLA IF statements into pure assembly language is very easy. The boolean expressions that the HLA IF supports were specifically chosen to expand into a few simple machine instructions. The following paragraphs discuss the conversion of each supported boolean expression into pure machine code.
if( flag_specification ) then <<stmts>> endif;
This form is, perhaps, the easiest HLA IF statement to convert. To execute the code immediately following the THEN keyword if a particular flag is set (or clear), all you need do is skip over the code if the flag is clear (set). This requires only a single conditional jump instruction for implementation as the following examples demonstrate:
// if( @c ) then inc( eax ); endif; jnc SkipTheInc; inc( eax ); SkipTheInc: // if( @ns ) then neg( eax ); endif; js SkipTheNeg; neg( eax ); SkipTheNeg:if( register ) then <<stmts>> endif;
This form of the IF statement uses the TEST instruction to check the specified register for zero. If the register contains zero (false), then the program jumps around the statements after the THEN clause with a JZ instruction. Converting this statement to assembly language requires a TEST instruction and a JZ instruction as the following examples demonstrate:
// if( eax ) then mov( false, eax ); endif; test( eax, eax ); jz DontSetFalse; mov( false, eax ); DontSetFalse: // if( al ) then mov( bl, cl ); endif; test( al, al ); jz noMove; mov( bl, cl ); noMove:if( !register ) then <<stmts>> endif;
This form of the IF statement uses the TEST instruction to check the specified register to see if it is zero. If the register is not zero (true), then the program jumps around the statements after the THEN clause with a JNZ instruction. Converting this statement to assembly language requires a TEST instruction and a JNZ instruction in a manner identical to the previous examples.
if( boolean_variable ) then <<stmts>> endif;
This form of the IF statement compares the boolean variable against zero (false) and branches around the statements if the variable does contain false. HLA implements this statement by using the CMP instruction to compare the boolean variable to zero and then it uses a JZ (JE) instruction to jump around the statements if the variable is false. The following example demonstrates the conversion:
// if( bool ) then mov( 0, al ); endif; cmp( bool, false ); je SkipZeroAL; mov( 0, al ); SkipZeroAL:if( !boolean_variable ) then <<stmts>> endif;
This form of the IF statement compares the boolean variable against zero (false) and branches around the statements if the variable contains true (i.e., the opposite condition of the previous example). HLA implements this statement by using the CMP instruction to compare the boolean variable to zero and then it uses a JNZ (JNE) instruction to jump around the statements if the variable contains true. The following example demonstrates the conversion:
// if( !bool ) then mov( 0, al ); endif; cmp( bool, false ); jne SkipZeroAL; mov( 0, al ); SkipZeroAL:if( mem_reg relop mem_reg_const ) then <<stmts>> endif;
HLA translates this form of the IF statement into a CMP instruction and a conditional jump that skips over the statements on the opposite condition specified by the relop operator. The following table lists the correspondence between operators and conditional jump instructions:
Here are a few examples of IF statements translated into pure assembly language that use expressions involving relational operators:
// if( al == ch ) then inc( cl ); endif; cmp( al, ch ); jne SkipIncCL; inc( cl ); SkipIncCL: // if( ch >= `a' ) then and( $5f, ch ); endif; cmp( ch, `a' ); jnae NotLowerCase and( $5f, ch ); NotLowerCase: // if( (type int32 eax ) < -5 ) then mov( -5, eax ); endif; cmp( eax, -5 ); jnl DontClipEAX; mov( -5, eax ); DontClipEAX: // if( si <> di ) then inc( si ); endif; cmp( si, di ); je DontIncSI; inc( si ); DontIncSI:if( reg/mem in LowConst..HiConst ) then <<stmts>> endif;
HLA translates this IF statement into a pair of CMP instructions and a pair of conditional jump instructions. It compares the register or memory location against the lower valued constant and jumps if less than (below) past the statements after the THEN clause. If the register or memory location's value is greater than or equal to LowConst, the code falls through to the second CMP/conditional jump pair that compares the register or memory location against the higher constant. If the value is greater than (above) this constant, a conditional jump instruction skips the statements in the THEN clause. Example:
// if( eax in 1000..125_000 ) then sub( 1000, eax ); endif; cmp( eax, 1000 ); jb DontSub1000; cmp( eax, 125_000 ); ja DontSub1000; sub( 1000, eax ); DontSub1000: // if( i32 in -5..5 ) then add( 5, i32 ); endif; cmp( i32, -5 ); jl NoAdd5; cmp( i32, 5 ); jg NoAdd5; add(5, i32 ); NoAdd5:if( reg/mem not in LowConst..HiConst ) then <<stmts>> endif;
This form of the HLA IF statement tests a register or memory location to see if its value is outside a specified range. The implementation is very similar to the code above exception you branch to the THEN clause if the value is less than the LowConst value or greater than the HiConst value and you branch over the code in the THEN clause if the value is within the range specified by the two constants. The following examples demonstrate how to do this conversion:
// if( eax not in 1000..125_000 ) then add( 1000, eax ); endif; cmp( eax, 1000 ); jb Add1000; cmp( eax, 125_000 ); jbe SkipAdd1000; Add1000: add( 1000, eax ); SkipAdd1000: // if( i32 not in -5..5 ) theen mov( 0, i32 ); endif; cmp( i32, -5 ); jl Zeroi32; cmp( i32, 5 ); jle SkipZero; Zeroi32: mov( 0, i32 ); SkipZero:if( reg8 in CSetVar/CSetConst ) then <<stmts>> endif;
This statement checks to see if the character in the specified eight-bit register is a member of the specified character set. HLA emits code that is similar to the following for instructions of this form:
movzx( reg8, eax ); bt( eax, CsetVar/CsetConst ); jnc SkipPastStmts; << stmts >> SkipPastStmts:This example modifies the EAX register (the code HLA generates does not, because it pushes and pops the register it uses). You can easily swap another register for EAX if you've got a value in EAX you need to preserve. In the worst case, if no registers are available, you can push EAX, execute the MOVZX and BT instructions, and then pop EAX's value from the stack. The following are some actual examples:
// if( al in {`a'..'z'} ) then or( $20, al ); endif; movzx( al, eax ); bt( eax, {`a'..'z'} ); // See if we've got a lower case char. jnc DontConvertCase; or( $20, al ); // Convert to uppercase. DontConvertCase:// if( ch in {`0'..'9'} ) then and( $f, ch ); endif; push( eax ); movzx( ch, eax ); bt( eax, {`a'..'z'} ); // See if we've got a lower case char. pop( eax ); jnc DontConvertNum; and( $f, ch ); // Convert to binary form. DontConvertNum:2.8.3 Implementing Complex IF Statements Using Complete Boolean Evaluation
The previous section did not discuss how to translate boolean expressions involving conjunction (AND) or disjunction (OR) into assembly language. This section will begin that discussion. There are two different ways to convert complex boolean expressions involving conjunction and disjunction into assembly language: using complete boolean evaluation or short circuit evaluation. This section discusses complete boolean evaluation. The next section discusses short circuit boolean evaluation, which is the scheme that HLA uses when converting complex boolean expressions to assembly language.
Using complete boolean evaluation to evaluate a boolean expression for an IF statement is almost identical to converting arithmetic expressions into assembly language. Indeed, the previous volume covers this conversion process (see "Logical (Boolean) Expressions" on page 604). About the only thing worth noting about that process is that you do not need to store the ultimate boolean result in some variable; once the evaluation of the expression is complete you check to see if you have a false (zero) or true (one, or non-zero) result to determine whether to branch around the THEN portion of the IF statement. As you can see in the examples in the preceding sections, you can often use the fact that the last boolean instruction (AND/OR) sets the zero flag if the result is false and clears the zero flag if the result is true. This lets you avoid explicitly testing the result. Consider the following IF statement and its conversion to assembly language using complete boolean evaluation:
if( (( x < y ) && ( z > t )) || ( a != b ) ) Stmt1;mov( x, eax ); cmp( eax, y ); setl( bl ); // Store x<y in bl. mov( z, eax ); cmp( eax, t ); setg( bh ); // Store z > t in bh. and( bh, bl ); // Put (x<y) && (z>t) into bl. mov( a, eax ); cmp( eax, b ); setne( bh ); // Store a != b into bh. or( bh, bl ); // Put (x<y) && (z>t) || (a != b) into bl je SkipStmt1; // Branch if result is false (OR sets Z-Flag if false).<< Code for Stmt1 goes here >>SkipStmt1:This code computes a boolean value in the BL register and then, at the end of the computation, tests this resulting value to see if it contains true or false. If the result is false, this sequence skips over the code associated with Stmt1. The important thing to note in this example is that the program will execute each and every instruction that computes this boolean result (up to the JE instruction).
For more details on complete boolean evaluation, see "Logical (Boolean) Expressions" on page 604.
2.8.4 Short Circuit Boolean Evaluation
If you are willing to spend a little more effort studying a complex boolean expression, you can usually convert it to a much shorter and faster sequence of assembly language instructions using short-circuit boolean evaluation. Short-circuit boolean evaluation attempts to determine whether an expression is true or false by executing only a portion of the instructions that compute the complete expression. By executing only a portion of the instructions, the evaluation is often much faster. For this reason, plus the fact that short circuit boolean evaluation doesn't require the use of any temporary registers, HLA uses short circuit evaluation when translating complex boolean expressions into assembly language.
To understand how short-circuit boolean evaluation works, consider the expression "A && B". Once we determine that A is false, there is no need to evaluate B since there is no way the expression can be true. If A and B represent sub-expressions rather than simple variables, you can begin to see the savings that are possible with short-circuit boolean evaluation. As a concrete example, consider the sub-expression "((x<y) && (z>t))" from the previous section. Once you determine that x is not less than y, there is no need to check to see if z is greater than t since the expression will be false regardless of z and t's values. The following code fragment shows how you can implement short-circuit boolean evaluation for this expression:
// if( (x<y) && (z>t) ) then ... mov( x, eax ); cmp( eax, y ); jnl TestFails; mov( z, eax ); cmp( eax, t ); jng TestFails; << Code for THEN clause of IF statement >> TestFails:Notice how the code skips any further testing once it determines that x is not less than y. Of course, if x is less than y, then the program has to test z to see if it is greater than t; if not, the program skips over the THEN clause. Only if the program satisfies both conditions does the code fall through to the THEN clause.
For the logical OR operation the technique is similar. If the first sub-expression evaluates to true, then there is no need to test the second operand. Whatever the second operand's value is at that point, the full expression still evaluates to true. The following example demonstrates the use of short-circuit evaluation with disjunction (OR):
// if( ch < `A' || ch > `Z' ) then stdout.put( "Not an upper case char" ); endif; cmp( ch, `A' ); jb ItsNotUC cmp( ch, `Z' ); jna ItWasUC; ItsNotUC: stdout.put( "Not an upper case char" ); ItWasUC:Since the conjunction and disjunction operators are commutative, you can evaluate the left or right operand first if it is more convenient to do so. As one last example in this section, consider the full boolean expression from the previous section:
// if( (( x < y ) && ( z > t )) || ( a != b ) ) Stmt1; mov( a, eax ); cmp( eax, b ); jne DoStmt1; mov( x, eax ); cmp( eax, y ); jnl SkipStmt1; mov( z, eax ); cmp( eax, t ); jng SkipStmt1; DoStmt1: << Code for Stmt1 goes here >> SkipStmt1:Notice how the code in this example chose to evaluate "a != b" first and the remaining sub-expression last. This is a common technique assembly language programmers use to write better code.
2.8.5 Short Circuit vs. Complete Boolean Evaluation
One fact about complete boolean evaluation is that every statement in the sequence will execute when evaluating the expression. Short-circuit boolean evaluation may not require the execution of every statement associated with the boolean expression. As you've seen in the previous two sections above, code based on short-circuit evaluation is usually shorter and faster1. So it would seem that short-circuit evaluation is the technique of choice when converting complex boolean expressions to assembly language.
Sometimes, unfortunately, short-circuit boolean evaluation may not produce the correct result. In the presence of side-effects in an expression, short-circuit boolean evaluation will produce a different result than complete boolean evaluation. Consider the following C/C++ example:
if( ( x == y ) && ( ++z != 0 )) stmt;Using complete boolean evaluation, you might generate the following code:
mov( x, eax ); // See if x == y cmp( eax, y ); sete( bl ); inc( z ); // ++z cmp( z, 0 ); // See if incremented z is zero. setne( bh ); and( bh, bl ); // Test x == y && ++z != 0 jz SkipStmt;<< code for stmt goes here >>SkipStmt:Using short-circuit boolean evaluation, you might generate the following code:
mov( x, eax ); // See if x == y cmp( eax, y ); jne SkipStmt; inc( z ); // ++z cmp( z, 0 ); // See if incremented z is zero. je SkipStmt;<< code for stmt goes here >>SkipStmt:Notice a very subtle, but important difference between these two conversions: if it turns out that x is equal to y, then the first version above still increments z and compares it to zero before it executes the code associated with stmt; the short-circuit version, on the other hand skips over the code that increments z if it turns out that x is equal to y. Therefore, the behavior of these two code fragments is different with respect to what happens to z if x is equal to y. Neither implementation is particularly wrong, depending on the circumstances you may or may not want the code to increment z if x is equal to y. However, it is important that you realize that these two schemes produce different results so you can choose an appropriate implementation if the effect of this code on z matters to your program.
Many programs take advantage of short-circuit boolean evaluation and rely upon the fact that the program may not evaluate certain components of the expression. The following C/C++ code fragment demonstrates what is probably the most common example that requires short-circuit boolean evaluation:
if( Ptr != NULL && *Ptr == `a' ) stmt;If it turns out that Ptr is NULL in this IF statement, then the expression is false and there is no need to evaluate the remainder of the expression (and, therefore, code that uses short-circuit boolean evaluation will not evaluate the remainder of this expression). This statement relies upon the semantics of short-circuit boolean evaluation for correct operation. Were C/C++ to use complete boolean evaluation, and the variable Ptr contained NULL, then the second half of the expression would attempt to dereference a NULL pointer (which tends to crash most programs). Consider the translation of this statement using complete and short-circuit boolean evaluation:
// Complete boolean evaluation: mov( Ptr, eax ); test( eax, eax ); // Check to see if EAX is zero (NULL is zero). setne( bl ); mov( [eax], al ); // Get *Ptr into AL. cmp( al, `a' ); sete( bh ); and( bh, bl ); jz SkipStmt;<< code for stmt goes here >>SkipStmt:Notice in this example that if Ptr contains NULL (zero), then this program will attempt to access the data at location zero in memory via the "mov( [eax], al );" instruction. Under most operating systems this will cause a memory access fault (general protection fault). Now consider the short-circuit boolean conversion:
// Short-circuit boolean evaluationmov( Ptr, eax ); // See if Ptr contains NULL (zero) and test( eax, eax ); // immediately skip past Stmt if this jz SkipStmt; // is the casemov( [eax], al ); // If we get to this point, Ptr contains cmp( al, `a' ); // a non-NULL value, so see if it points jne SkipStmt; // at the character `a'.<< code for stmt goes here >>SkipStmt:As you can see in this example, the problem with dereferencing the NULL pointer doesn't exist. If Ptr contains NULL, this code skips over the statements that attempt to access the memory address Ptr contains.
2.8.6 Efficient Implementation of IF Statements in Assembly Language
Encoding IF statements efficiently in assembly language takes a bit more thought than simply choosing short-circuit evaluation over complete boolean evaluation. To write code that executes as quickly as possible in assembly language you must carefully analyze the situation and generate the code appropriately. The following paragraphs provide some suggestions you can apply to your programs to improve their performance.
A mistake programmers often make is the assumption that data is random. In reality, data is rarely random and if you know the types of values that your program commonly uses, you can use this knowledge to write better code. To see how, consider the following C/C++ statement:
if(( a == b ) && ( c < d )) ++i;Since C/C++ uses short-circuit evaluation, this code will test to see if a is equal to b. If so, then it will test to see if c is less than d. If you expect a to be equal to b most of the time but don't expect c to be less than d most of the time, this statement will execute slower than it should. Consider the following HLA implementation of this code:
mov( a, eax ); cmp( eax, b ); jne DontIncI; mov( c, eax ); cmp( eax, d ); jnl DontIncI; inc( i ); DontIncI:As you can see in this code, if a is equal to b most of the time and c is not less than d most of the time, you will have to execute the first three instructions nearly every time in order to determine that the expression is false. Now consider the following implementation of the above C/C++ statement that takes advantage of this knowledge and the fact that the "&&" operator is commutative:
mov( c, eax ); cmp( eax, d ); jnl DontIncI; mov( a, eax ); cmp( eax, b ); jne DontIncI; inc( i ); DontIncI:In this example the code first checks to see if c is less than d. If most of the time c is less than d, then this code determines that it has to skip to the label DontIncI after executing only three instructions in the typical case (compared with six instructions in the previous example). This fact is much more obvious in assembly language than in a high level language; this is one of the main reasons that assembly programs are often faster than their high level language counterparts: optimizations are more obvious in assembly language than in a high level language. Of course, the key here is to understand the behavior of your data so you can make intelligent decisions such as the one above.
Even if your data is random (or you can't determine how the input values will affect your decisions), there may still be some benefit to rearranging the terms in your expressions. Some calculations take far longer to compute than others. For example, the DIV instruction is much slower than a simple CMP instruction. Therefore, if you have a statement like the following you may want to rearrange the expression so that the CMP comes first:
if( (x % 10 = 0 ) && (x != y ) ++x;Converted to assembly code, this IF statement becomes:
mov( x, eax ); // Compute X % 10 cdq(); // Must sign extend EAX -> EDX:EAX imod( 10, edx:eax ); // Remember, remainder goes into EDX test( edx, edx ); // See if EDX is zero. jnz SkipIF mov( x, eax ); cmp( eax, y ); je SkipIF inc( x ); SkipIF:The IMOD instruction is very expensive (often 50-100 times slower than most of the other instructions in this example). Unless it is 50-100 times more likely than the remainder is zero rather than x is equal to y, it would be better to do the comparison first and the remainder calculation afterwards:
mov( x, eax ); cmp( eax, y ); je SkipIF mov( x, eax ); // Compute X % 10 cdq(); // Must sign extend EAX -> EDX:EAX imod( 10, edx:eax ); // Remember, remainder goes into EDX test( edx, edx ); // See if EDX is zero. jnz SkipIF inc( x ); SkipIF:Of course, in order to rearrange the expression in this manner, the code must not assume the use of short-circuit evaluation semantics (since the && and || operators are not commutative if the code must compute one subexpression before another).
Although there is a lot of good things to be said about structured programming techniques, there are some drawbacks to writing structured code. Specifically, structured code is sometimes less efficient than unstructured code. Most of the time this is tolerable because unstructured code is difficult to read and maintain; it is often acceptable to sacrifice some performance in exchange for maintainable code. In certain instances, however, you may need all the performance you can get. In those rare instances you might choose to compromise the readability of you code in order to gain some additional performance.
One classic way to do this is to use code movement to move code your program rarely uses out of the way of code that executes most of the time. For example, consider the following pseudo C/C++ statement:
if( See_If_an_Error_Has_Ocurred ) { << Statements to execute if no error >> } else { << Error handling statements >> }In normal code, one does not expect errors to be frequent. Therefore, you would normally expect the THEN section of the above IF to execute far more often than the ELSE clause. The code above could translate into the following assembly code:
cmp( See_If_an_Error_Has_Ocurred, true ); je HandleTheError << Statements to execute if no error >> jmp EndOfIF; HandleTheError: << Error handling statements >> EndOfIf:Notice that if the expression is false this code falls through to the normal statements and then jumps over the error handling statements. Instructions that transfer control from one point in your program to another (e.g., JMP instructions) tend to be slow. It is much faster to execute a sequential set of instructions rather than jump all over the place in your program. Unfortunately, the code above doesn't allow this. One way to rectify this problem is to move the ELSE clause of the code somewhere else in your program. That is, you could rewrite the code as follows:
cmp( See_If_an_Error_Has_Ocurred, true ); je HandleTheError << Statements to execute if no error >> EndOfIf:At some other point in your program (typically after a JMP instruction) you would insert the following code:
HandleTheError: << Error handling statements >> jmp EndOfIf;Note that the program isn't any shorter. The JMP you removed from the original sequence winds up at the end of the ELSE clause. However, since the ELSE clause rarely executes, moving the JMP instruction from the THEN clause (which executes frequently) to the ELSE clause is a big performance win because the THEN clause executes using only straight-line code. This technique is surprisingly effective in many time-critical code segments.
There is a difference between writing destructured code and writing unstructured code. Unstructured code is written in an unstructured way to begin with. It is generally hard to read, difficult to maintain, and it often contains defects. Destructured code, on the other hand, starts out as structured code and you make a conscious decision to eliminate the structure in order to gain a small performance boost. Generally, you've already tested the code in its structured form before destructuring it. Therefore, destructured code is often easier to work with than unstructured code.
Calculation Rather than Branching
On many processors in the 80x86 family, branches are very expensive compared to many other instructions (perhaps not as bad as IMOD or IDIV, but typically an order of magnitude worse than instructions like ADD and SUB). For this reason it is sometimes better to execute more instructions in a sequence rather than fewer instructions that involve branching. For example, consider the simple assignment "EAX = abs(EAX);" Unfortunately, there is no 80x86 instruction that computes the absolute value of an integer value. The obvious way to handle this is with an instruction sequence like the following:
test( eax, eax ); jns ItsPositive; neg( eax ); ItsPositive:However, as you can plainly see in this example, it uses a conditional jump to skip over the NEG instruction (that creates a positive value in EAX if EAX was negative). Now consider the following sequence that will also do the job:
// Set EDX to $FFFF_FFFF if EAX is negative, $0000_0000 if EAX is // zero or positive: cdq(); // If EAX was negative, the following code inverts all the bits in EAX, // otherwise it has no effect on EAX. xor( edx, edx); // If EAX was negative, the following code adds one to EAX, otherwise // it doesn't modify EAX's value. and( 1, edx ); // EDX = 0 or 1 (1 if EAX was negative). add( edx, eax );This code will invert all the bits in EAX and then add one to EAX if EAX was negative prior to the sequence (i.e., it takes the two's complement [negates] the value in EAX). If EAX was zero or positive, then this code does not change the value in EAX.
Note that this sequence takes four instructions rather than the three the previous example requires. However, since there are no transfer of control instructions in this sequence, it may execute faster on many CPUs in the 80x86 family.
2.8.7 SWITCH/CASE Statements
The HLA (Standard Library) SWITCH statement takes the following form :
switch( reg32 ) case( const1) <<stmts1>> case( const2 ) <<stmts2>> . . . case( constn ) <<stmtsn >> default // Note that the default section is optional <<stmtsdefault >> endswitch;When this statement executes, it checks the value of register against the constants const1 ... constn. If a match is found then the corresponding statements execute. HLA places a few restrictions on the SWITCH statement. First, the HLA SWITCH statement only allows a 32-bit register as the SWITCH expression. Second, all the constants appearing as CASE clauses must be unique. The reason for these restrictions will become clear in a moment.
Most introductory programming texts introduce the SWITCH/CASE statement by explaining it as a sequence of IF..THEN..ELSEIF statements. They might claim that the following two pieces of HLA code are equivalent:
switch( eax ) case(0) stdout.put("I=0"); case(1) stdout.put("I=1"); case(2) stdout.put("I=2"); endswitch;if( eax = 0 ) then stdout.put("I=0") elseif( eax = 1 ) then stdout.put("I=1") elseif( eax = 2 ) then stdout.put("I=2"); endif;While semantically these two code segments may be the same, their implementation is usually different. Whereas the IF..THEN..ELSEIF chain does a comparison for each conditional statement in the sequence, the SWITCH statement normally uses an indirect jump to transfer control to any one of several statements with a single computation. Consider the two examples presented above, they could be written in assembly language with the following code:
// IF..THEN..ELSE form:mov( i, eax ); test( eax, eax ); // Check for zero. jnz Not0; stdout.put( "I=0" ); jmp EndCase; Not0: cmp( eax, 1 ); jne Not1; stdou.put( "I=1" ); jmp EndCase; Not1: cmp( eax, 2 ); jne EndCase; stdout.put( "I=2" ); EndCase: // Indirect Jump Version readonly JmpTbl:dword[3] := [ &Stmt0, &Stmt1, &Stmt2 ]; . . . mov( i, eax ); jmp( JmpTbl[ eax*4 ] );Stmt0: stdout.put( "I=0" ); jmp EndCase; Stmt1: stdout.put( "I=1" ); jmp EndCase; Stmt2: stdout.put( "I=2" ); EndCase:The implementation of the IF..THEN..ELSEIF version is fairly obvious and doesn't need much in the way of explanation. The indirect jump version, however, is probably quite mysterious to you; so let's consider how this particular implementation of the SWITCH statement works.
Remember that there are three common forms of the JMP instruction (see "Unconditional Transfer of Control (JMP)" on page 753). The standard unconditional JMP instruction, like the "jmp EndCase;" instructions in the previous examples, transfer control directly to the statement label specified as the JMP operand. The second form of the JMP instruction (i.e., "jmp Reg32;") transfers control to the memory location specified by the address found in a 32-bit register. The third form of the JMP instruction, the one the example above uses, transfers control to the instruction specified by the contents of a dword memory location. As this example clearly illustrates, that memory location can use any addressing mode. You are not limited to the displacement-only addressing mode. Now let's consider exactly how this second implementation of the SWITCH statement works.
To begin with, a SWITCH statement requires that you create an array of pointers with each element containing the address of a statement label in your code (those labels must be attached to the sequence of instructions to execute for each case in the SWITCH statement). In the example above, the JmpTbl array serves this purpose. Note that this code initializes JmpTbl with the address of the statement labels Stmt0, Stmt1, and Stmt2. The program places this array in the READONLY section because the program should never change these values during execution.
- Warning: whenever you initialize an array with a set of address of statement labels as in this example, the declaration section in which you declare the array (e.g., READONLY in this case) must be in the same procedure that contains the statement labels2.
During the execution of this code sequence, the program loads the EAX register with I's value. Then the program uses this value as an index into the JmpTbl array and transfers control to the four-byte address found at the specified location. For example, if EAX contains zero, the "jmp( JmpTbl[eax*4]);" instruction will fetch the dword at address JmpTbl+0 (eax*4=0). Since the first double word in the table contains the address of Stmt0, the JMP instruction will transfer control to the first instruction following the Stmt0 label. Likewise, if I (and therefore, EAX) contains one, then the indirect JMP instruction fetches the double word at offset four from the table and transfers control to the first instruction following the Stmt1 label (since the address of Stmt1 appears at offset four in the table). Finally, if I/EAX contains two, then this code fragment transfers control to the statements following the Stmt2 label since it appears at offset eight in the JmpTbl table.
Two things should become readily apparent: the more (consecutive) cases you have, the more efficient the jump table implementation becomes (both in terms of space and speed) over the IF/ELSEIF form. Except for trivial cases, the SWITCH statement is almost always faster and usually by a large margin. As long as the CASE values are consecutive, the SWTICH statement version is usually smaller as well.
What happens if you need to include non-consecutive CASE labels or you cannot be sure that the SWITCH value doesn't go out of range? With the HLA SWITCH statement, such an occurrence will transfer control to the first statement after the ENDSWITCH clause. However, this doesn't happen in the example above. If variable I does not contain zero, one, or two, the result of executing the code above is undefined. For example, if I contains five when you execute the code in the previous example, the indirect JMP instruction will fetch the dword at offset 20 (5*4) in JmpTbl and transfer control to that address. Unfortunately, JmpTbl doesn't have six entries; so the program will wind up fetching the value of the third double word following JmpTbl and using that as the target address. This will often crash your program or transfer control to an unexpected location. Clearly this code does not behave like the HLA SWITCH statement, nor does it have desirable behavior.
The solution is to place a few instructions before the indirect JMP to verify that the SWITCH selection value is within some reasonable range. In the previous example, we'd probably want to verify that I's value is in the range 0..2 before executing the JMP instruction. If I's value is outside this range, the program should simply jump to the EndCase label (this corresponds to dropping down to the first statement after the ENDSWITCH clause). The following code provides this modification:
readonly JmpTbl:dword[3] := [ &Stmt0, &Stmt1, &Stmt2 ]; . . . mov( i, eax ); cmp( eax, 2 ); // Verify that I is in the range ja EndCase; // 0..2 before the indirect JMP. jmp( JmpTbl[ eax*4 ] );Stmt0: stdout.put( "I=0" ); jmp EndCase; Stmt1: stdout.put( "I=1" ); jmp EndCase; Stmt2: stdout.put( "I=2" ); EndCase:Although the example above handles the problem of selection values being outside the range zero through two, it still suffers from a couple of severe restrictions:
- The cases must start with the value zero. That is, the minimum CASE constant has to be zero in this example.
- The case values must be contiguous; there cannot be any gaps between any two case values.
Solving the first problem is easy and you deal with it in two steps. First, you must compare the case selection value against a lower and upper bounds before determining if the case value is legal, e.g.,
// SWITCH statement specifying cases 5, 6, and 7: // WARNING: this code does *NOT* work. Keep reading to find out why. mov( i, eax ); cmp( eax, 5 ); jb EndCase cmp( eax, 7 ); // Verify that I is in the range ja EndCase; // 5..7 before the indirect JMP. jmp( JmpTbl[ eax*4 ] );Stmt5: stdout.put( "I=5" ); jmp EndCase; Stmt6: stdout.put( "I=6" ); jmp EndCase; Stmt7: stdout.put( "I=7" ); EndCase:As you can see, this code adds a pair of extra instructions, CMP and JB, to test the selection value to ensure it is in the range five through seven. If not, control drops down to the EndCase label, otherwise control transfers via the indirect JMP instruction. Unfortunately, as the comments point out, this code is broken. Consider what happens if variable i contains the value five: The code will verify that five is in the range five through seven and then it will fetch the dword at offset 20 (5*@size(dword)) and jump to that address. As before, however, this loads four bytes outside the bounds of the table and does not transfer control to a defined location. One solution is to subtract the smallest case selection value from EAX before executing the JMP instruction. E.g.,
// SWITCH statement specifying cases 5, 6, and 7: // WARNING: there is a better way to do this. Keep reading. readonly JmpTbl:dword[3] := [ &Stmt5, &Stmt6, &Stmt7 ]; . . . mov( i, eax ); cmp( eax, 5 ); jb EndCase cmp( eax, 7 ); // Verify that I is in the range ja EndCase; // 5..7 before the indirect JMP. sub( 5, eax ); // 5->0, 6->1, 7->2. jmp( JmpTbl[ eax*4 ] );Stmt5: stdout.put( "I=5" ); jmp EndCase; Stmt6: stdout.put( "I=6" ); jmp EndCase; Stmt7: stdout.put( "I=7" ); EndCase:By subtracting five from the value in EAX this code forces EAX to take on the values zero, one, or two prior to the JMP instruction. Therefore, case selection value five jumps to Stmt5, case selection value six transfers control to Stmt6, and case selection value seven jumps to Stmt7.
There is a sneaky way to slightly improve the code above. You can eliminate the SUB instruction by merging this subtraction into the JMP instruction's address expression. Consider the following code that does this:
// SWITCH statement specifying cases 5, 6, and 7: readonly JmpTbl:dword[3] := [ &Stmt5, &Stmt6, &Stmt7 ]; . . . mov( i, eax ); cmp( eax, 5 ); jb EndCase cmp( eax, 7 ); // Verify that I is in the range ja EndCase; // 5..7 before the indirect JMP. jmp( JmpTbl[ eax*4 - 5*@size(dword)] );Stmt5: stdout.put( "I=5" ); jmp EndCase; Stmt6: stdout.put( "I=6" ); jmp EndCase; Stmt7: stdout.put( "I=7" ); EndCase:The HLA SWITCH statement provides a DEFAULT clause that executes if the case selection value doesn't match any of the case values. E.g.,
switch( ebx ) case( 5 ) stdout.put( "ebx=5" ); case( 6 ) stdout.put( "ebx=6" ); case( 7 ) stdout.put( "ebx=7" ); default stdout.put( "ebx does not equal 5, 6, or 7" ); endswitch;Implementing the equivalent of the DEFAULT clause in pure assembly language is very easy. Just use a different target label in the JB and JA instructions at the beginning of the code. The following example implements an HLA SWITCH statement similar to the one immediately above:
// SWITCH statement specifying cases 5, 6, and 7 with a DEFAULT clause: readonly JmpTbl:dword[3] := [ &Stmt5, &Stmt6, &Stmt7 ]; . . . mov( i, eax ); cmp( eax, 5 ); jb DefaultCase; cmp( eax, 7 ); // Verify that I is in the range ja DefaultCase; // 5..7 before the indirect JMP. jmp( JmpTbl[ eax*4 - 5*@size(dword)] );Stmt5: stdout.put( "I=5" ); jmp EndCase; Stmt6: stdout.put( "I=6" ); jmp EndCase; Stmt7: stdout.put( "I=7" ); jmp EndCase; DefaultCase: stdout.put( "I does not equal 5, 6, or 7" ); EndCase:The second restriction noted earlier, that the case values need to be contiguous, is easy to handle by inserting extra entries into the jump table. Consider the following HLA SWITCH statement:
switch( ebx ) case( 1 ) stdout.put( "ebx = 1" ); case( 2 ) stdout.put( "ebx = 2" ); case( 4 ) stdout.put( "ebx = 4" ); case( 8 ) stdout.put( "ebx = 8" ); default stdout.put( "ebx is not 1, 2, 4, or 8" ); endswitch;The minimum switch value is one and the maximum value is eight. Therefore, the code before the indirect JMP instruction needs to compare the value in EBX against one and eight. If the value is between one and eight, it's still possible that EBX might not contain a legal case selection value. However, since the JMP instruction indexes into a table of dwords using the case selection table, the table must have eight dword entries. To handle the values between one and eight that are not case selection values, simply put the statement label of the default clause (or the label specifying the first instruction after the ENDSWITCH if there is no DEFAULT clause) in each of the jump table entries that don't have a corresponding CASE clause. The following code demonstrates this technique:
readonly JmpTbl2: dword := [ &Case1, &Case2, &dfltCase, &Case4, &dfltCase, &dfltCase, &dfltCase, &Case8 ]; . . . cmp( ebx, 1 ); jb dfltCase; cmp( ebx, 8 ); ja dfltCase; jmp( JmpTbl2[ ebx*4 - 1*@size(dword)] ); Case1: stdout.put( "ebx = 1" ); jmp EndOfSwitch; Case2: stdout.put( "ebx = 2" ); jmp EndOfSwitch; Case4: stdout.put( "ebx = 4" ); jmp EndOfSwitch; Case8: stdout.put( "ebx = 8" ); jmp EndOfSwitch; dfltCase: stdout.put( "ebx is not 1, 2, 4, or 8" ); EndOfSwitch:There is a problem with this implementation of the SWITCH statement. If the CASE values contain non-consecutive entries that are widely spaced the jump table could become exceedingly large. The following SWITCH statement would generate an extremely large code file:
switch( ebx ) case( 1 ) stmt1; case( 100 ) stmt2; case( 1_000 ) stmt3; case( 10_000 ) stmt4; default stmt5; endswitch;In this situation, your program will be much smaller if you implement the SWITCH statement with a sequence of IF statements rather than using an indirect jump statement. However, keep one thing in mind- the size of the jump table does not normally affect the execution speed of the program. If the jump table contains two entries or two thousand, the SWITCH statement will execute the multi-way branch in a constant amount of time. The IF statement implementation requires a linearly increasing amount of time for each case label appearing in the case statement.
Probably the biggest advantage to using assembly language over a HLL like Pascal or C/C++ is that you get to choose the actual implementation. In some instances you can implement a SWITCH statement as a sequence of IF..THEN..ELSEIF statements, or you can implement it as a jump table, or you can use a hybrid of the two:
switch( eax ) case( 0 ) stmt0; case( 1 ) stmt1; case( 2 ) stmt2; case( 100 ) stmt3; default stmt4; endswitch;cmp( eax, 100 ); je DoStmt3; cmp( eax, 2 ); ja TheDefaultCase; jmp( JmpTbl[ eax*4 ]); etc.Of course, you could do this in HLA using the following code high-level control structures:
if( ebx = 100 ) then stmt3 else switch( eax ) case(0) stmt0; case(1) stmt1; case(2) stmt2; Otherwise stmt4 endswitch; endif;But this tends to destroy the readability of the program. On the other hand, the extra code to test for 100 in the assembly language code doesn't adversely affect the readability of the program (perhaps because it's so hard to read already). Therefore, most people will add the extra code to make their program more efficient.
The C/C++ SWITCH statement is very similar to the HLA SWITCH statement3. There is only one major semantic difference: the programmer must explicitly place a BREAK statement in each CASE clause to transfer control to the first statement beyond the SWITCH. This BREAK corresponds to the JMP instruction at the end of each CASE sequence in the assembly code above. If the corresponding BREAK is not present, C/C++ transfers control into the code of the following CASE. This is equivalent to leaving off the JMP at the end of the CASE'S sequence:
switch (i) { case 0: stmt1; case 1: stmt2; case 2: stmt3; break; case 3: stmt4; break; default: stmt5; }This translates into the following 80x86 code:
readonly JmpTbl: dword[4] := [ &case0, &case1, &case2, &case3 ]; . . . mov( i, ebx ); cmp( ebx, 3 ); ja DefaultCase; jmp( JmpTbl[ ebx*4 ]); case0: stmt1; case1: stmt2; case2: stmt3; jmp EndCase; // Emitted for the break stmt. case3: stmt4; jmp EndCase; // Emitted for the break stmt. DefaultCase: stmt5; EndCase:1Note that this does not always mean that the program will run faster. Jumps (conditional or otherwise) are often very slow executing instructions. Sometimes it's faster to execute several instructions in a row rather than execute a few instructions that include a conditional jump.
2If the SWITCH statement appears in your main program, you must declare the array in the declaration section of your main program.
3The HLA Standard Library SWITCH statement actually provides an option to support C semantics. See the HLA Standard Library documentation for details.
|